Velure
Cloud-native e-commerce platform with event-driven Go microservices, EKS infra via Terraform, and real-time order status over SSE.
Velure is my undergraduate capstone (TCC): an event-driven e-commerce backend on AWS — Go microservices, RabbitMQ, EKS, observability, and real-time order updates over SSE. This is the long version: not a feature tour, but a walk through the decisions, the alternatives I weighed, and the trade-offs I knowingly accepted. The project is educational, so the bar wasn't "production-ready commerce" — it was "every choice has to survive a why did you do it that way question."
The system in one paragraph
A shopper browses a catalog, places an order, and watches its status flip from CREATED to PROCESSING to COMPLETED or FAILED in real time. That single path — browse → order → status — is the whole scope, on purpose. I cut breadth (no recommendations, no reviews, no admin panel) so I could go deep on the things a backend engineer actually gets asked about: service boundaries, async processing, exactly-once-ish semantics, infrastructure as code, CI/CD, and observability.
Architecture
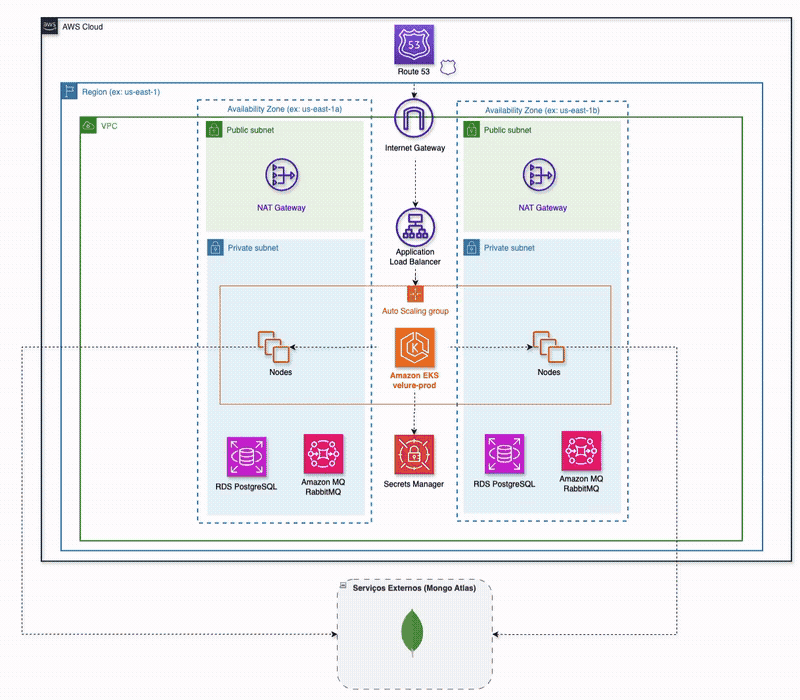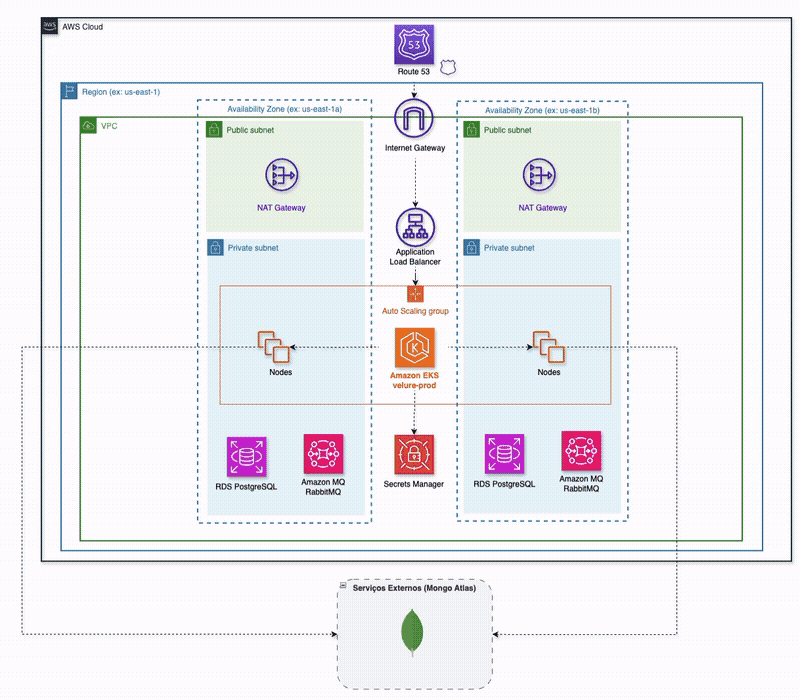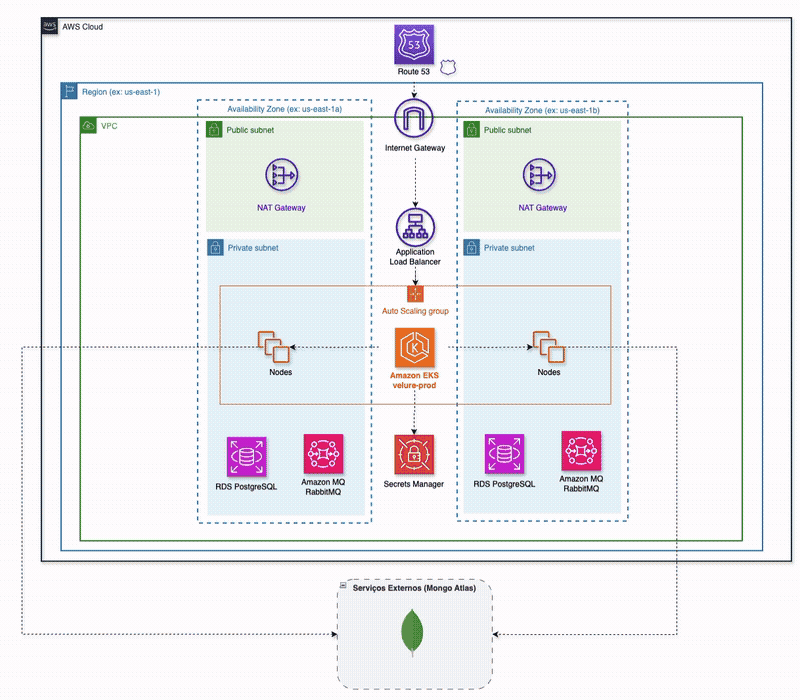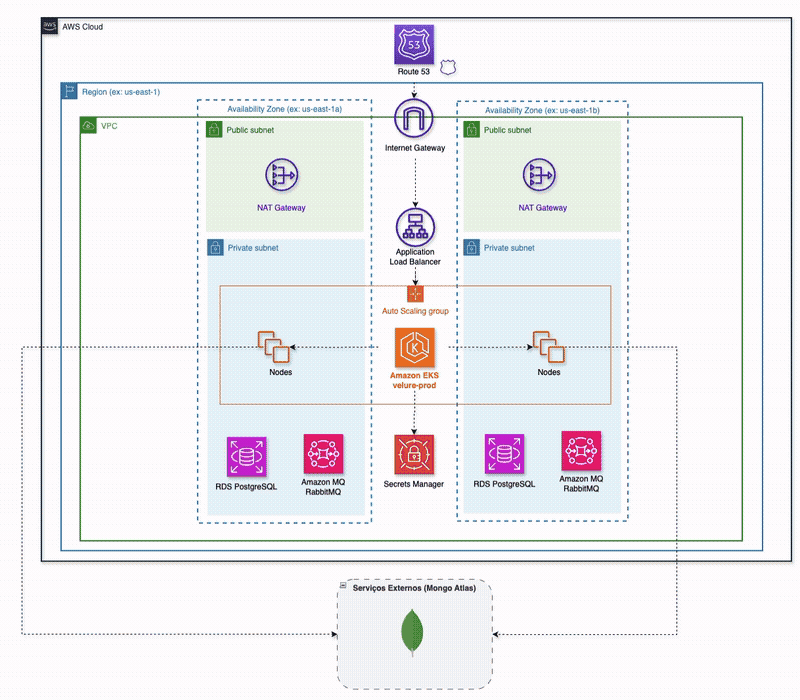
Five services sit behind the edge — AWS ALB Ingress Controller in production (Caddy locally):
ui-service— React/Vite SPA (nginx in prod)auth-service— Go + Gin, Postgres for users, Redis as a JWT-validation cacheproduct-service— Go + Fiber, MongoDB catalogpublish-order-service— Go + net/http, Postgres + RabbitMQ + SSE; owns order intake and the status streamprocess-order-service— Go + net/http, RabbitMQ only, no database of its own
Each service owns its data store; nobody reaches into anyone else's schema. A shared Go module under shared/ exports only a structured logger and DTOs — no business logic — so the coupling between services is explicit and visible in the import graph, not smuggled through a "common" grab-bag.
The order flow is asynchronous end to end. POST /api/orders hits publish-order-service, which persists the order in Postgres and publishes order.created to the orders exchange. process-order-service consumes it, calls product-service over HTTP for an inventory check, runs simulated payment logic, and publishes the terminal status back to RabbitMQ. publish-order-service consumes that status, updates Postgres, and pushes it to the browser over an SSE stream keyed on the order ID.
Why these choices
This project was built with learning as the main goal. Each decision below follows the same shape: the context, the options I considered, why I rejected the others, and the trade-off I accepted.
Event-driven over synchronous REST between the order services
Context. Order creation needs an inventory check and a payment step. The simplest thing is one synchronous Go call chain: publish → HTTP → process → HTTP → product, all inside the request.
Why async instead. I put RabbitMQ between publish and process. That buys three things: retry semantics for free (a crashed consumer redelivers, an HTTP call just fails), independent deploys (I can ship process-order-service without touching the request path), and independent scaling (the consumer can fan out without the intake service growing with it). It also models the real shape of the domain — "your order is being processed" is genuinely a background job, not a blocking call the user should wait on.
The trade-off I accepted. Async is strictly harder to operate. Local debugging now spans a broker, end-to-end latency is harder to reason about, and there's an extra managed dependency in prod (Amazon MQ). I decided the operational realism was worth it — for a system whose point is demonstrating distributed patterns, collapsing it into one synchronous call would have defeated the exercise.
RabbitMQ over SQS
Context. On AWS, the path of least resistance for a message queue is SQS: fully managed, near-zero ops, dirt cheap at this scale, and it integrates with everything.
Why RabbitMQ anyway — honestly. I chose RabbitMQ because I wanted the operational challenge, not because SQS would have been technically worse here. SQS would almost certainly have been the lower-effort, lower-cost choice. But I wanted hands-on time with the things SQS hides from you: declaring a topic exchange and routing keys, wiring dead-letter exchanges by hand, bootstrapping the topology deterministically, and running a stateful broker (Amazon MQ for RabbitMQ) instead of an opaque managed queue. The whole TCC is a learning vehicle, and "run the broker that teaches you the most" was a legitimate objective.
The trade-off I accepted. More moving parts, a stateful component to provision and pay for, and topology I have to own (see the bootstrap job below) instead of an SQS queue that just exists. For this workload SQS would likely be the better choice; here RabbitMQ was worth the extra cost for what it taught me.
EKS over ECS Fargate
Context. Five containers and a few datastores do not need Kubernetes. ECS Fargate would have been cheaper, simpler, and faster to stand up.
Why EKS. The pedagogical goal explicitly included the CNCF surface — Helm charts, ServiceMonitor CRDs, the kube-prometheus-stack, an Ingress controller, IRSA. None of that exists on ECS in the same form. The operational complexity is the curriculum, not an accident.
The trade-off I accepted. ~$72/month just for the control plane, plus the cognitive overhead of running Kubernetes for a workload that doesn't demand it. For a commercial project at this size I'd reach for Fargate or even App Runner; here, the complexity is the deliverable.
Polyglot persistence: MongoDB for catalog, Postgres for orders and auth
Context. It would be simpler to run one database engine everywhere.
Why split. Catalog documents are heterogeneous and read-heavy — products have varying attributes per category, and the access pattern is "fetch this product" far more than "join across products." A document store fits that shape. Orders and users are the opposite: they need transactional writes (the outbox below literally depends on it) and relational queries, so Postgres. Redis sits in front of auth as a JWT-validation cache, so a token check is a memory lookup instead of a round trip.
The trade-off I accepted. Three storage engines is three times the operational surface — backups, exporters, failure modes, and connection management all multiply. I accepted it because forcing one engine to do both jobs would have meant either relational gymnastics over documents or a document store pretending to be transactional. Keeping each schema honest was worth the extra ops.
SSE over WebSocket for order status
Context. The browser needs live status updates. WebSocket is the reflexive choice for "real-time."
Why SSE. The updates are unidirectional (server → client) and short-lived (they stop at the terminal status). WebSocket's full-duplex channel is wasted capability here. Server-Sent Events run over plain HTTP, pass through most proxies untouched, and reconnect with Last-Event-ID for free — no extra protocol, no upgrade handshake. WebSocket would only have earned its keep if the cart needed live bidirectional collaboration.
The trade-off I accepted. SSE is one-way and capped by the browser's per-domain connection limit. For "watch this order until it's done," those limits never bite, so I took the simpler protocol.
The SSE stream
The status transitions happen out of band from the original HTTP request, so the UI can't just read the response — it opens GET /api/me/orders/{id}/events and an in-memory registry fans events out to whichever connections are subscribed to that order.
func (h *SSEHandler) StreamOrderStatus(w http.ResponseWriter, r *http.Request) {
// ... auth + order lookup elided ...
w.Header().Set("Content-Type", "text/event-stream")
w.Header().Set("Cache-Control", "no-cache")
w.Header().Set("Connection", "keep-alive")
events := make(chan model.Order, 10)
h.registry.Register(orderID, events)
defer h.registry.Unregister(orderID, events)
ticker := time.NewTicker(30 * time.Second)
defer ticker.Stop()
for {
select {
case <-r.Context().Done():
return
case updated := <-events:
data, _ := json.Marshal(updated)
fmt.Fprintf(w, "data: %s\n\n", data)
w.(http.Flusher).Flush()
case <-ticker.C:
fmt.Fprintf(w, ": keepalive\n\n")
w.(http.Flusher).Flush()
}
}
}Two non-obvious details. The registry channel is buffered (make(..., 10)) and the broadcaster writes with select { case ch <- order: default: } — a slow client drops events instead of stalling the whole fan-out, so one wedged browser tab can't back-pressure everyone else. And the 30-second keepalive comment exists to defeat idle-connection timeouts on the AWS NLB and most corporate proxies, which silently kill a stream that goes quiet.
The outbox and idempotency
This is the decision I'm proudest of, because it started as a bug.
The original mistake. publish-order-service wrote the order to Postgres and then published order.created to RabbitMQ — two separate operations. A crash in the gap between them committed the order but never emitted the event. The order would sit in CREATED forever, invisible to the rest of the system. A classic dual-write hazard.
Options I weighed.
- Two-phase commit (XA) across Postgres and RabbitMQ — correct in theory, but heavyweight, poorly supported, and a coordinator I'd have to operate. Rejected.
- CDC with Debezium tailing the Postgres WAL — robust and decoupled, but a whole Kafka-Connect-shaped dependency for one event stream. Disproportionate at this scale. Rejected.
- Transactional outbox — write the order and an
outbox_eventsrow in the same Postgres transaction, then a relay drains the table to RabbitMQ. Chosen.
func (r *Relay) processBatch(ctx context.Context) error {
tx, events, err := r.repo.FetchUnpublished(ctx, r.batchSize)
if err != nil { return err }
defer tx.Rollback()
ids := make([]string, 0, len(events))
for _, evt := range events {
if err := r.publisher.PublishWithConfirm(ctx, evt); err != nil {
return err // rollback → next tick retries the whole batch
}
ids = append(ids, evt.ID)
}
if err := r.repo.MarkPublished(ctx, tx, ids); err != nil { return err }
return tx.Commit()
}The relay is a hybrid push/pull: it listens on a Postgres NOTIFY outbox_new channel for sub-second latency, and falls back to a 10-second poll to recover any notifications dropped across a listener reconnect. FOR UPDATE SKIP LOCKED on the fetch lets multiple replicas share the table without stepping on each other. On the consume side, process-order-service writes SET event:<id> 1 NX EX 86400 to Redis and drops any redelivered message that's already there — so at-least-once delivery on the wire becomes effectively-once processing, with no distributed transaction anywhere.
Messaging topology and dead-letter queues
The broker isn't just a pipe — its topology is declared up front by a rabbitmq-bootstrap Kubernetes Job that runs before the consumers start, so exchanges and queues exist deterministically instead of being created ad hoc on first connect. A topic exchange orders routes order.created to process-order-queue, and the order.processing|completed|failed keys to publish-order-status-updates.
Every consumer queue is paired with a Dead Letter Exchange. process-order-queue declares x-dead-letter-exchange: orders.dlx (a fanout) feeding process-order-queue.dlq; the publish side mirrors it with publish.dlx. The contract: transient failures retry in place, but a parse error, a permanent failure, or a message past maxRetries gets Nack(false, false) — it leaves the main queue and lands in the DLQ for inspection or replay. The alternative, requeueing a poison message forever, would park a broken event at the head of the queue and stall every healthy message behind it. A DLQ turns "infinite loop" into "quarantine and move on." Each service also connects with its own AMQP user (PUBLISHER_RABBITMQ_USER, PROCESS_RABBITMQ_USER), so a leaked credential can't read the other stream.
Infrastructure as code
The AWS footprint is a root Terraform module composing seven sub-modules: vpc (two-AZ public/private split with a single NAT gateway — because two would really hurt the wallet, and even one isn't exactly cheap), security-groups (least-privilege; RDS is reachable only from the node security groups), eks, rds (two isolated Postgres instances — one for auth, one for orders, both db.t4g.micro), amazonmq (managed RabbitMQ), route53, and secrets-manager. The whole stack stands up with make cloud-up in ~30 minutes and tears down with make cloud-down.
Cost as a first-class constraint. The whole stack lands at ~$140–150/month, and keeping a lab like this running in the cloud isn't cheap. That's why there's a single NAT gateway instead of one per AZ, db.t4g.micro instances on the free tier, and a deliberately weekend-destroyable footprint.
Secrets never touch Git or plain manifests. A ClusterSecretStore points the External Secrets Operator at AWS Secrets Manager, authenticated through IRSA — the operator's service account assumes an IAM role via the cluster's OIDC provider, so there are no static AWS keys living in the cluster. ExternalSecret resources then materialize Secrets Manager entries into native Kubernetes Secrets that pods consume as env vars. The alternative — committing sealed secrets or hand-creating kubectl secrets — either leaks into Git history or drifts from any source of truth.
Deployment shape. Each service ships as its own Helm chart, deployed into a domain-scoped namespace (authentication, product, order, frontend). Charts default to two replicas with a HorizontalPodAutoscaler (2→10, scaling at 80% CPU / 65% memory), tight requests == limits (which lands every pod in Kubernetes' Guaranteed QoS class — last to be evicted under node memory pressure, lowest OOM score), and /health liveness and readiness probes. The Ingress is the detail I like most: instead of one ALB per service, every chart annotates its Ingress with alb.ingress.kubernetes.io/group.name: velure-public, so the AWS Load Balancer Controller merges them onto a single shared ALB with ordered routing rules — one load balancer's cost, many services' routes.
CI/CD
CI is a monorepo-aware GitHub Actions pipeline. A determine-changes job runs dorny/paths-filter to detect which service directories changed, and downstream jobs are gated on those outputs — so a UI-only commit never rebuilds five Go services, while a change under shared/ correctly fans out to every Go service that depends on it. That gating is the difference between a monorepo that's pleasant and one where every commit costs ten minutes of CI.
Per-language logic lives in reusable workflows (go-service.yml, node-service.yml) called with the service name and path:
- Go services →
go test ./... -coverprofile -covermode=atomic, a (non-blocking) SonarCloud scan, then a Buildx image build pushed to Docker Hub with GitHub Actions layer cache (cache-from/to: type=gha). Tags come fromdocker/metadata-action(branch, PR,sha, andlateston the default branch). - UI service → Bun install +
vitestcoverage + SonarCloud, same Buildx/cache path.
Deploys are decoupled into a third reusable workflow (deploy-service.yml) that fires only on push to the default branch, and only for services that actually changed. It configures AWS credentials, refreshes kubeconfig against the velure-production EKS cluster in us-east-1, maps the service to its {namespace, chart}, and runs helm upgrade --install --atomic --wait --timeout 10m. --atomic is the safety net — a failed rollout auto-rolls-back instead of leaving a half-deployed release serving traffic. There's also an explicit retry loop: if Helm reports a pending operation (a concurrent release holding the lock), it backs off 60 seconds and retries up to five times rather than hard-failing the pipeline.
No ArgoCD, on purpose (for now). Deploys are push-based from CI; there's no ArgoCD or Flux in the loop. Two reasons: time, and wanting to first understand the raw mechanics — Helm release state, kubeconfig context, rollout status, atomic rollback — without a GitOps controller papering over them. The natural next step is to flip to pull-based reconciliation: the cluster pulling desired state from a manifests repo instead of CI pushing helm upgrade. But only once the push path stops teaching me anything.
Observability
Observability is a full three-pillar stack, wired the same way locally and in-cluster so a dashboard built on my laptop works unchanged on EKS.
- Metrics — Prometheus scrapes every service's
/metricsendpoint. In EKS those targets are declared asServiceMonitorCRDs (one per service) consumed by kube-prometheus-stack; locally it's static scrape config. Infrastructure and datastores are covered by exporters: node-exporter, cAdvisor, and dedicated exporters for PostgreSQL, MongoDB, Redis, and RabbitMQ — so a "is the queue backing up?" or "is the cache hit rate dropping?" question has an answer without instrumenting the app. Recording rules pre-aggregate the expensive queries (request rates, p95/p99 latency, error ratios) so dashboards stay cheap to render. - Logs — every service logs structured JSON through the shared
loggermodule; Promtail ships them to Loki, labelled byservice_typeand level, queried in Grafana right next to the metrics. - Dashboards — eight Grafana dashboards (a services overview, one per microservice, plus Postgres/Mongo/Redis/RabbitMQ and a logs view), version-controlled as JSON and loaded by provisioning, not click-ops — so the dashboards are reviewable in a PR and survive a cluster rebuild.
- Alerting —
PrometheusRuleresources define alerts across four domains: application (HighErrorRate >1%,CriticalErrorRate >5%,HighLatency p99 >1s,ServiceDown), infrastructure (CPU/memory >80%,PodCrashLooping), database (Postgres connection-pool and cache-hit-ratio, Redis memory), and messaging (RabbitMQQueueGrowing,RabbitMQNoConsumers). AlertManager handles routing, with Slack/email/PagerDuty receivers as a config swap.
The honest gap: no distributed tracing. A request crossing browser → publish-order-service → RabbitMQ → process-order-service produces four separate log streams and zero correlated spans. When an order takes eight seconds instead of two hundred milliseconds, metrics show that it was slow and logs show what each service did — but nothing stitches the hops into a single timeline, so "which step ate the budget?" stays detective work instead of a query. That's the top item on the roadmap below (OTel → Jaeger), and I'd rather name the gap than paper over it.
Edge: Caddy locally, ALB Ingress in prod
Locally, Caddy replaces a nginx + certbot + multi-file compose setup with an ~80-line Caddyfile: automatic HTTPS and one config for the whole dev loop. In EKS, the AWS ALB Ingress Controller takes over the same edge role through per-service Ingress manifests. Different mechanism, same abstraction — the application code never knows which one is in front of it, and there's no shared edge config to keep in sync between environments.
What I'd do differently
order_id — today FIFO is global, not per-aggregate.publish-order-service can scale past one replica without sticky sessions.Links
- Repository: github.com/icl00ud/velure
- License: MIT